一、接入 Hugging Face 大模型 API
Hugging Face 提供了便捷的 Inference API,让开发者无需部署模型即可调用各种大语言模型。本节将详细介绍如何获取 API Token 并调用 Llama 3.2 模型。
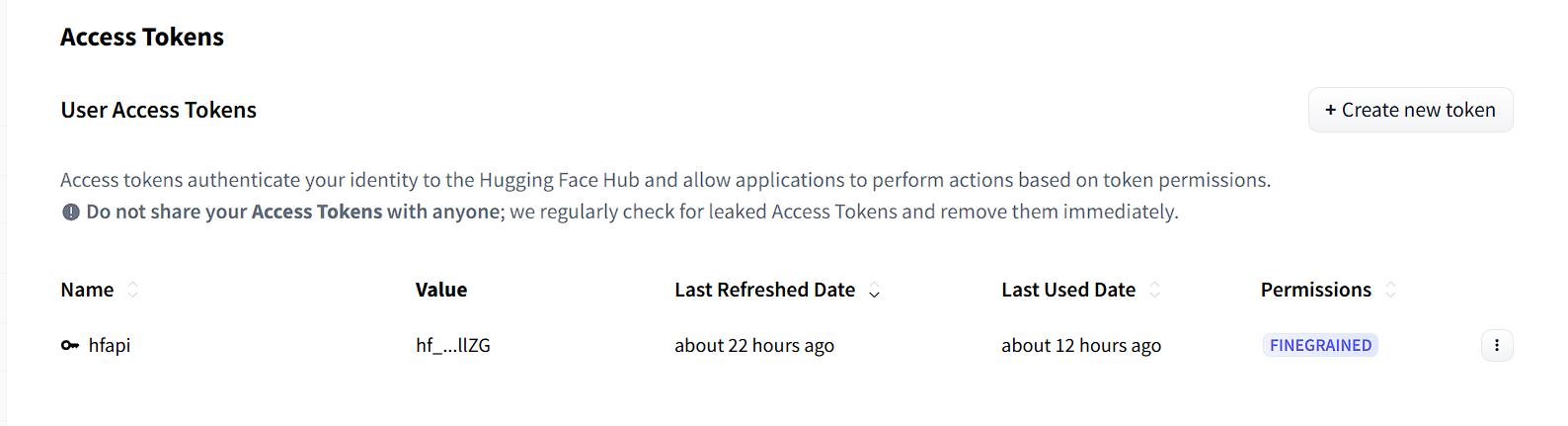
1.1 获取 Access Token
首先需要在 Hugging Face 平台上获取访问令牌:
- 登录账户:访问🔗 Hugging Face 并登录你的账户
- 进入 Token 管理页面:点击右上角头像 →
Access Tokens,或直接访问🔗 Token 设置页 - 创建新 Token:点击
Create new token按钮 - 配置 Token 权限:
- 输入 Token 名称(如
my-api-token) - 勾选所需权限,推荐勾选
Read权限用于 API 调用
- 输入 Token 名称(如
- 生成并保存:点击
Create token,复制生成的HF_TOKEN并妥善保存
⚠️ 注意:Token 只会显示一次,请务必保存好。如果遗忘,需要重新生成。
1.2 选择并查看模型 API
Hugging Face 托管了海量预训练模型,许多模型提供了API的调用接口,当然也不是每个都提供,这里以 meta-llama/Llama-3.2-1B-Instruct为例:
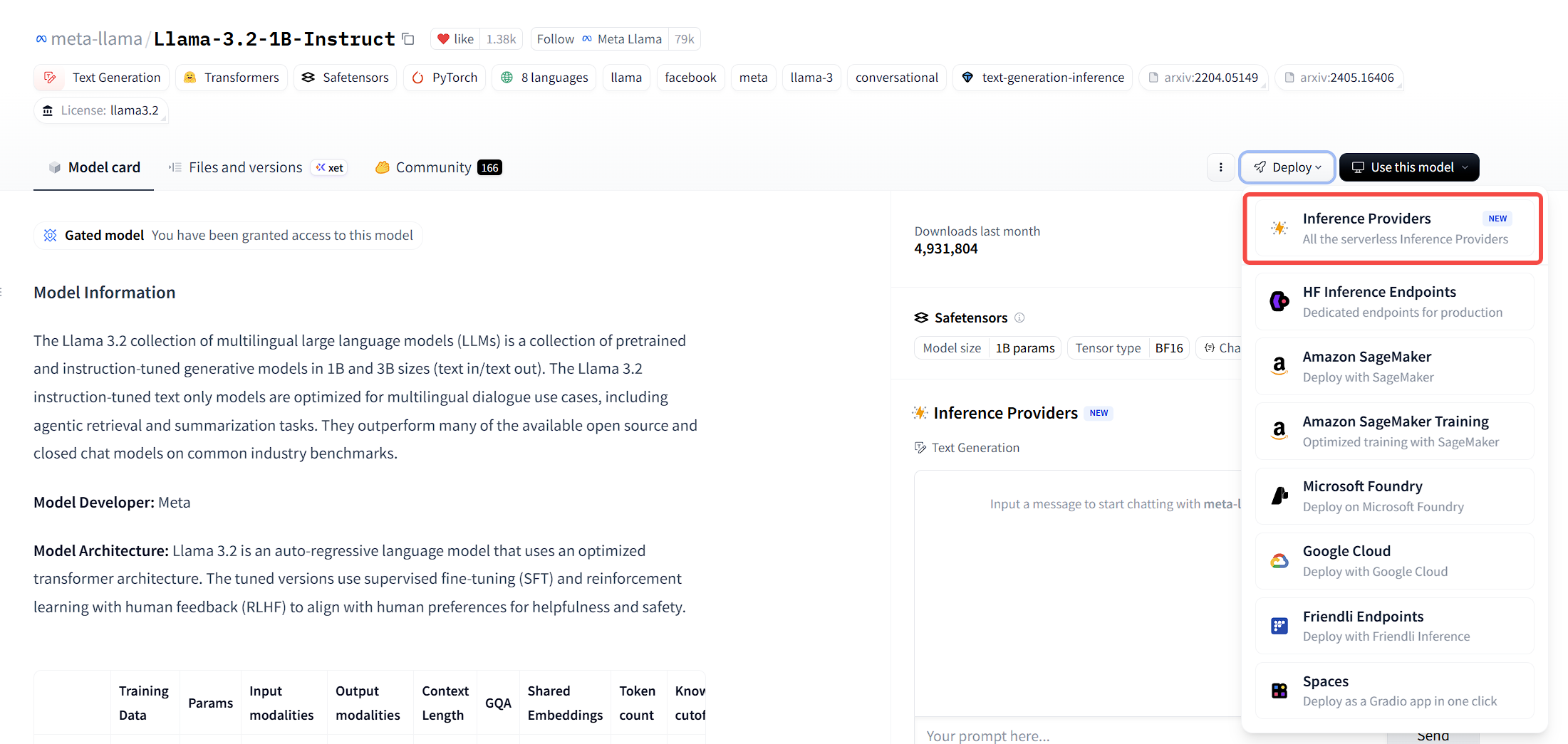
- 搜索模型:在 Hugging Face 首页搜索框输入 [
meta-llama/Llama-3.2-1B-Instruct],或直接访问 🔗 模型页面 - 进入模型页面:点击搜索结果进入模型详情页
- 查看 API 调用方式:找到
Deploy→Inference Providers - 选择服务商:可以看到不同服务商的 API 端点和调用示例
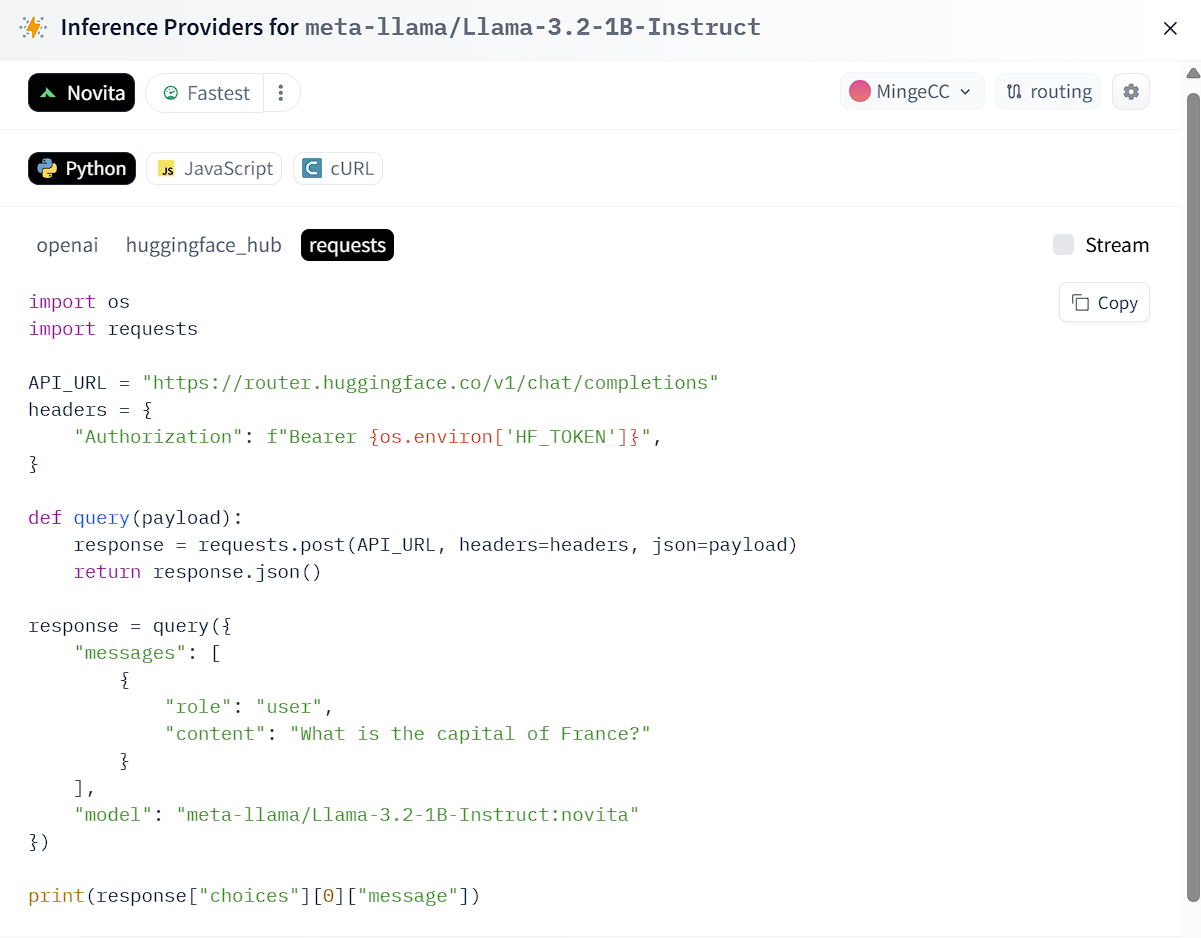
1.3 使用 Python 调用 API
以下是一个完整的 Python 示例,使用 requests 库调用 Llama 3.2 模型,此时需要传入 HF_TOKEN :
import os
import requests
os.environ["HF_TOKEN"] = "XXXX"
API_URL = "https://router.huggingface.co/v1/chat/completions"
headers = {
"Authorization": f"Bearer {os.environ['HF_TOKEN']}",
"Content-Type": "application/json",
}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload, timeout=60)
response.raise_for_status()
return response.json()
response = query({
"messages": [
{
"role": "user",
"content": "你是哪个模型,多大的?"
}
],
"model": "meta-llama/Llama-3.2-1B-Instruct:novita"
})
print(response["choices"][0]["message"]["content"])
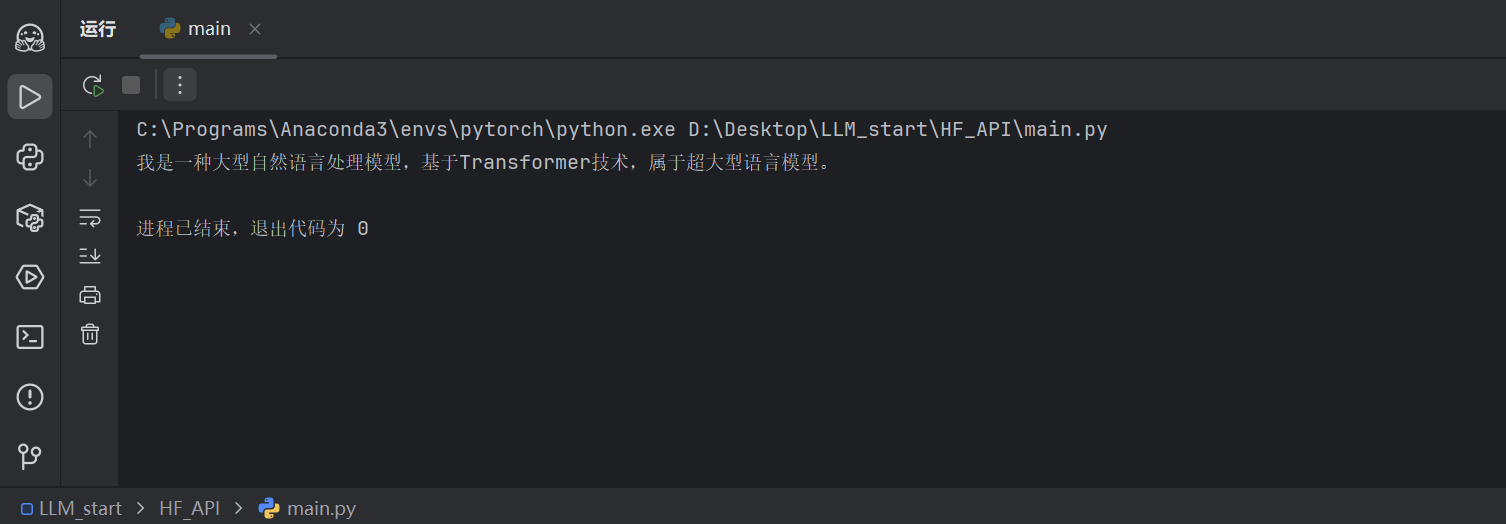
1.4 API 输出结果
下图为 meta-llama/Llama-3.2-1B-Instruct 的输出结果
1.5 常见问题
Q: Token 验证失败怎么办?
A: 检查 Token 是否正确复制,确认 Token 有足够的权限(需要 Read 权限)。
Q: 模型调用超时?
A: 部分模型需要较长加载时间,首次调用可能超时。可以增加 timeout 参数或稍后重试。
Q: 如何查看可用模型?
A: 访问 🔗 Hugging Face Models 页面,筛选支持 Inference API 的模型
二、将Llama-3.2-1B部署到本地(CPU/CUDA)
2.1 部署接口
Hugging Face提供了部署接口,在use this model中如图所示Transformers:本地 Python 调用,适合 CPU/CUDA 单机部署;Inference Providers/HuggingChat:云端推理与网页交互,不属于本地部署;Google Colab/Kaggle:云端 Notebook,适合实验和演示;vLLM/SGLang/Docker Model Runner:本地或服务器端的服务化部署方案。
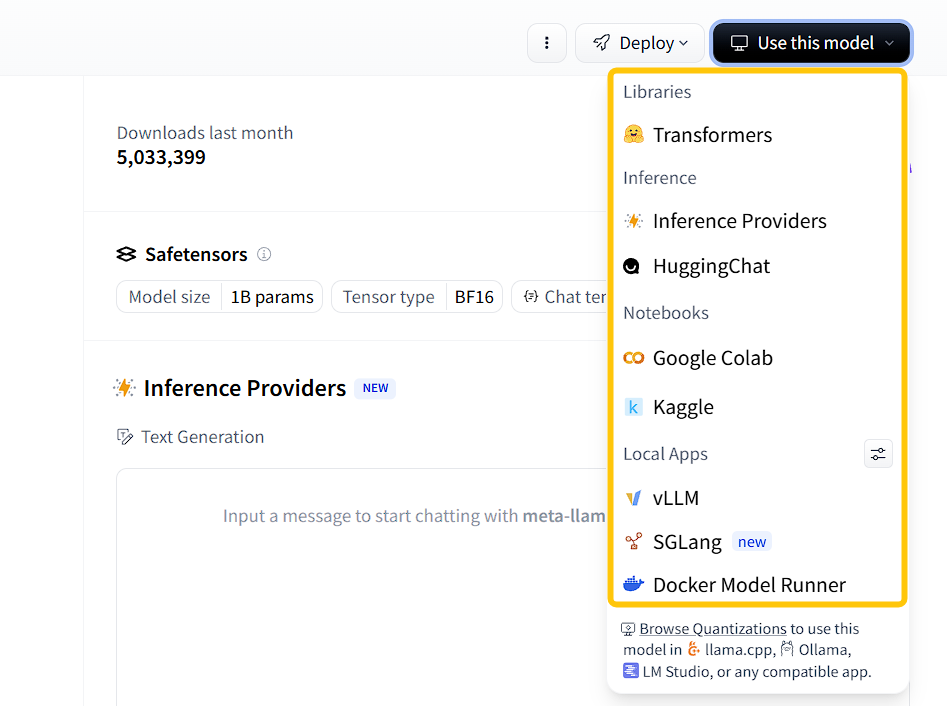
2.2 环境准备
- 首先需要获取Llama模型下载的许可,在 Model card 中填入申请信息即可
- 准备本地 Hugging Face 令牌,先
conda activate your_env激活环境- 安装
huggingface_hub:python -m pip install -U huggingface_hub - 在命令行中登陆验证
hf auth login --force,输入前文保存的HF_TOKEN,即可验证成功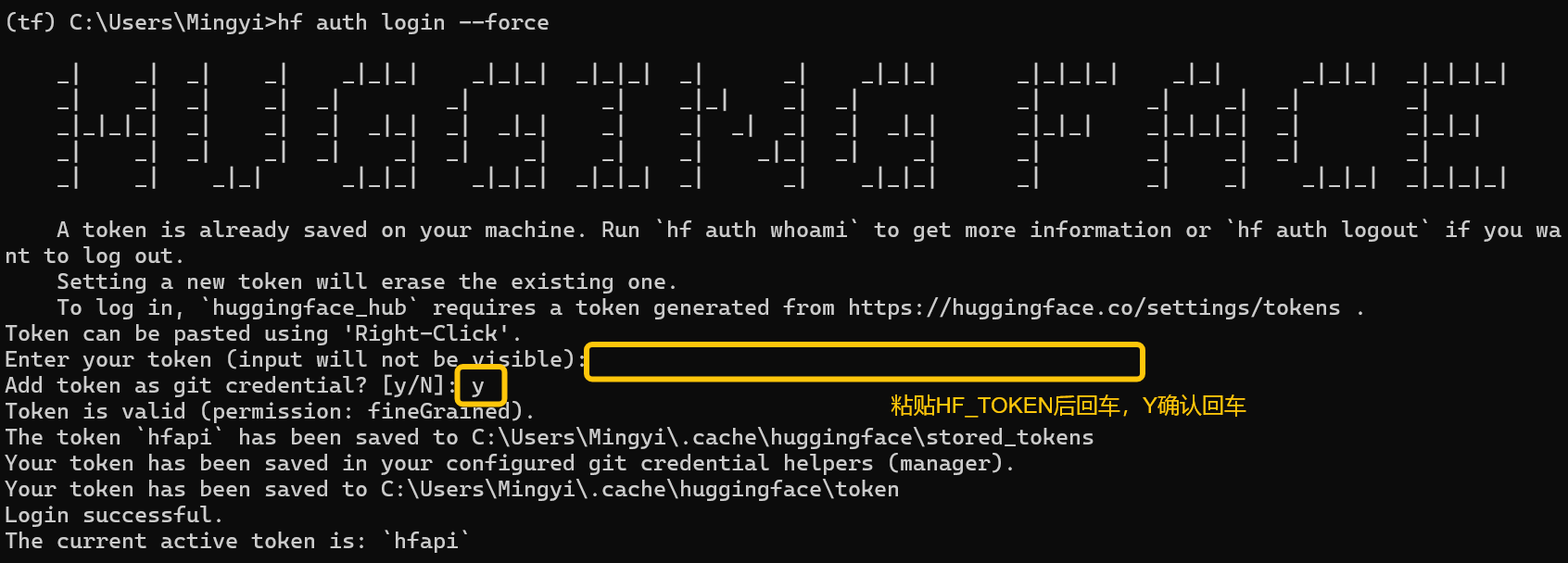
- 安装
- 安装必要的库如Transformers
python -m pip install -U transformers,pyhton-m表示安装在当前环境,-U表示升级到新版本
2.3 模型部署调用
基于🔗 Transformer Library 导入模型并调用
2.3.1 使用pipeline作为加载器
from transformers import pipeline
pipe = pipeline("text-generation", model="meta-llama/Llama-3.2-1B-Instruct", device="cuda")
messages = [
{"role": "user", "content": "Who are you?"},
]
pipe(messages)
说明:
代码中为cuda运行,切换
device="cpu"即可使用cpu运行运行后开始下载模型,目录
C:\Users\用户名\.cache\huggingface\hub,下载后可将模型文件夹移动至项目文件夹中 再次调用时,应将代码中的模型修改为model=r"项目地址\models--meta-llama--Llama-3.2-1B-Instruct\snapshots\9213176726f574b556790deb65791e0c5aa438b6"Llama3.2输出结果与模型目录结构如下图
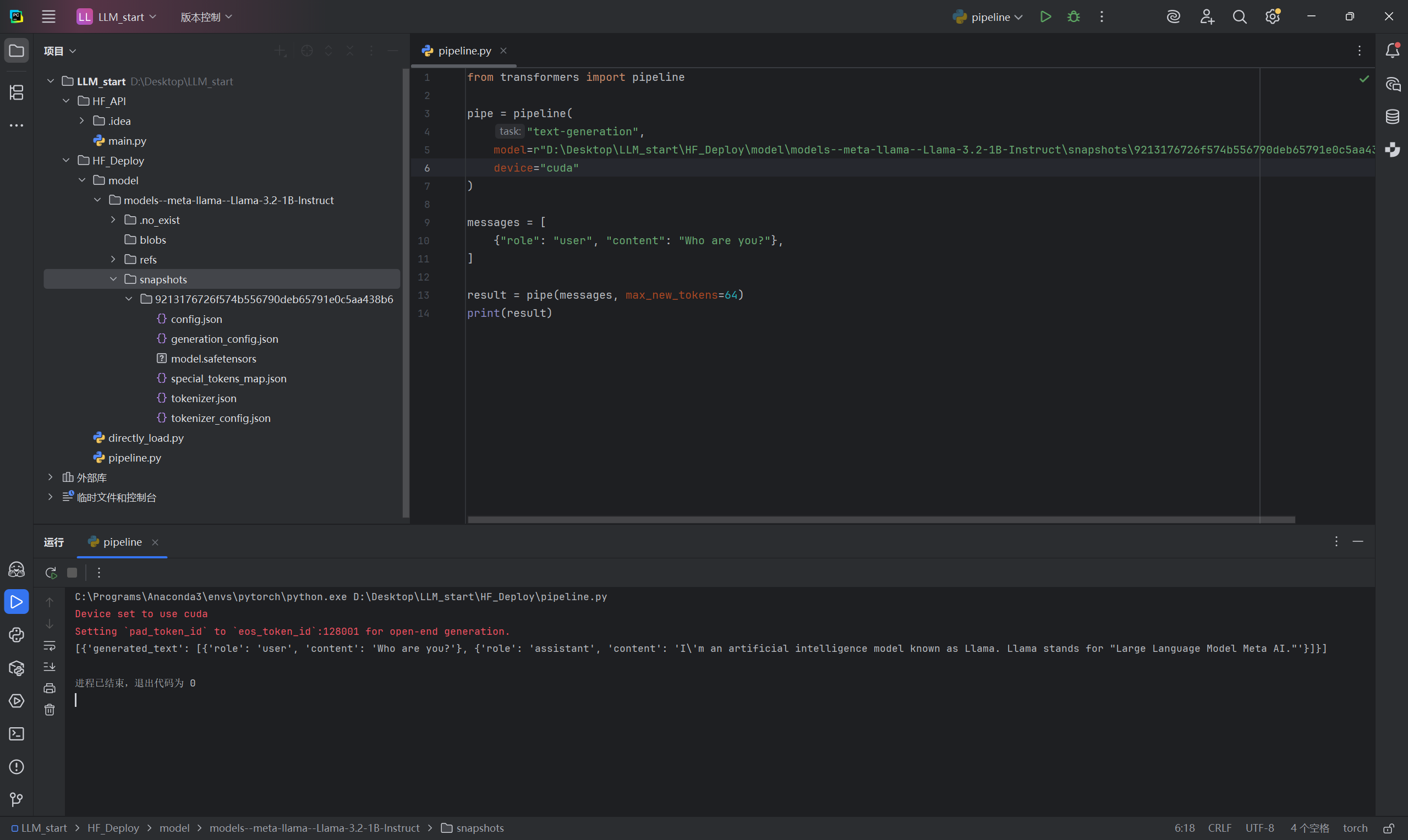
2.3.2 从模型直接加载
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-1B-Instruct") # 模型移动到项目时修改此处
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.2-1B-Instruct") # 模型移动到项目时修改此处
messages = [
{"role": "user", "content": "Who are you?"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
说明同上